
PyTorch For FPGA Part 2: Basic FPGA Optimizations
- Dylan T Bespalko

- Feb 24, 2020
- 3 min read
Updated: Feb 24, 2020

Feb 2020: I am currently looking for work in the San Francisco Bay Area in RF & Optical Communications. Contact me on LinkedIn
The function result = a + alpha*b is implemented under my PyTorch FPGA repo using Xilinx Vitis High-Level Synthesis (HLS) and 5 CMake sub-projects:
/CMakeLists.txt: Top-Level C++ Project File
/build: The temporary build folder used in each optimization step below.
/platform: Builds FPGA config file for a given FPGA device -> emconfig.json
/kernel: Compiles the Programmable Logic (PL) into a shared object with v++ -> vfadd.xo
/link_: Links the Programmable Logic (PL) into a binary with v++ -> torch.xclbin
/host: Builds the Processor System (PS) C++ binary that runs on the host machine. ->./test
/xrt: Configures the Xilinx Runtime configuration file -> xrt.ini
Each optimization step creates a new sub-directory in the kernel, link, and host directories.
The following environment variables are used in this tutorial:
XCL_PLATFORM="xilinx_u200_xdma_201830_2" # Xilinx XRT
XCL_EMULATION_MODE="sw_emu" # sw_emu | hw_emu | hw
XCL_OPT_INDEX=4 # 1: buffered 2: dataflow 3: distributed 4: vec
XCL_CU=1 # Number of Computational Units (CU)
1. Memory Buffering (XCL_OPT_INDEX = 1 # buffered)
The initial kernel (PL) solution buffers arrays of length 1024 through the FPGA computation:
This function consists of three annotated for loops:
read: Reads inputs from global memory into local FPGA memory.
vadd: Computs a + alpha * b.
write: Writes result from local FPGA memory to global memory.
#define LOCAL_MEM_SIZE 1024 tells the FPGA to transfer 1024 values between global and local memory at a time. Increasing this value increases the area the FPGA must allocate for local memory, while increasing or decreasing this value could improve the throughput between the PL and PS by buffering the data.
The initial host (PS) solution connects to the fpga, loads torch.xclbin binary, and calls the vadd kernel.
The test_vadd() function is a unit test-case that runs the add kernel on the FPGA as follows:
For those unfamiliar with PyTorch, AT_DISPATCH_FLOATING_TYPES is a #define that expands into a C++ switch statement, which dispatches the code for each tensor dtype (<scalar_t>). The run_kernel() function accepts a Pytorch TensorIterator (iter) containing references to the result, a, and b tensors, while alpha is cast to the appropriate data type and passed by value. The run_kernel() function is responsible for communicating between the PS host code and the PL kernel code as follows:
This can be broken down into 6 steps:
Launch the add kernel.
Allocate the memory buffers for the tensor arguments into the kernel (result, a, and b).
Set the kernel arguments including additional scalar arguments (alpha, stride, offset).
Enqueue the input memory transfer to transfer the input data from PS to PL.
Enqueue the kernel tasks to execute the add task.
Enqueue the output memory transfer to transfer the output data from the PL to PS.
In run_kernel(), OpenCL establishes a client-server relationship between the PS and PL. Input arguments offset and stride are needed to map between the PS strided memory layout and the PL local memory. Now you can build this code and test it as follows:
sw_emu:
hw_emu:
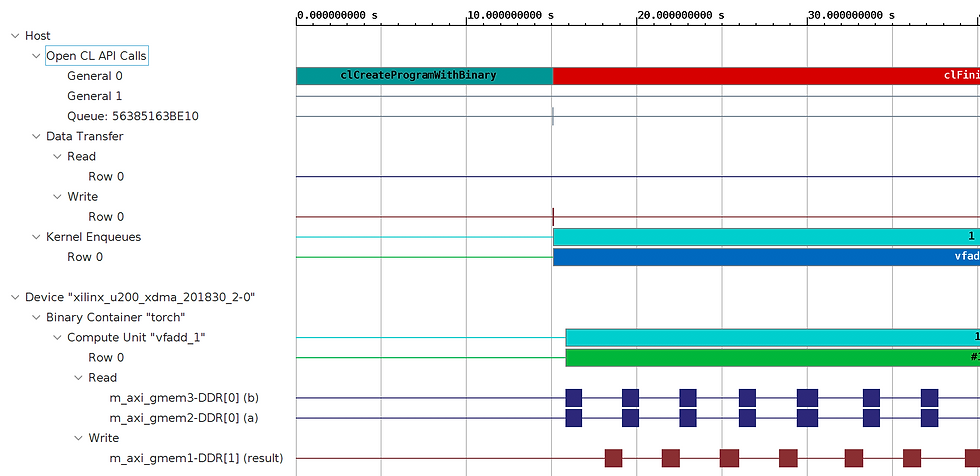
The Vitis Analyzer only profiles the software memory transfers between the PS and PL, however the Vivado Analyzer can be used profile hardware signals in the FPGA. When using LOCAL_MEM_SIZE = 1024, we spend an equal amount of time reading inputs, adding them inside the PL, and then writing outputs back to the PS. This is the minimum requirement for running an function on the FPGA. Now let's speed it up!
2. Pipelining/Dataflow (XCL_OPT_INDEX = 2 # dataflow)
These techniques are commonly implemented at the hardware level in most processors, however the FPGA gives the end-user more options.
Pipeline: Reduces the initiation interval between successive function or loop iterations allowing command-level concurrent operation.
Dataflow: Allows task-level pipelining to start the next task using intermediate results from the previous task allowing task-level concurrent operation.












Let's modify the kernel code by pipelining the contents of each loop and by moving each loop into its own function which is called using dataflow.
Notice that the vadd for loop is pipelined, starting a new iteration ever clock cycle (II=1), while the read_dataflow, vadd_dataflow, and write)dataflow functions are using dataflow to call the next function as soon as the data stream (his::stream) becomes available. Now you can build this code and test it as follows:
sw_emu:
hw_emu:

The timeline above shows that this additional performance is achieved by steaming data through the read, vadd, and write functions one sample at a time.
3. Fixed-Point Precision (Not Implemented)
Instead of transferring 32-bit floating-point values to the FPGA, it is common to send a 16-bit fixed-point container consisting of two integer values representing the numeric value to the left and right of the decimal point. This will improve CU bound computations because integer math is faster. It will also speed up IO bound computations by 2X, because 16-bit fixed point numbers sufficiently represent 32-bit floating-point operations in most applications.

Comments